Биномиальное распределение
Биномиальное распределение - одно из важнейших распределений вероятностей дискретно изменяющейся случайной величины. Биномиальным распределением называется распределение вероятностей числа m наступления события А в n взаимно независимых наблюдениях . Часто событие А называют "успехом" наблюдения, а противоположное ему событие - "неуспехом", но это обозначение весьма условное.
Условия биномиального распределения :
- в общей сложности проведено n испытаний, в которых событие А может наступить или не наступить;
- событие А в каждом из испытаний может наступить с одной и той же вероятностью p ;
- испытания являются взаимно независимыми.
Вероятность того, что в n испытаниях событие А наступит именно m раз, можно вычислить по формуле Бернулли:
![]()
![]() ,
,
где p - вероятность наступления события А ;
q = 1 - p - вероятность наступления противоположного события .
Разберёмся, почему биномиальное распределение описанным выше образом связано с формулой Бернулли . Событие - число успехов при n испытаниях распадается на ряд вариантов, в каждом из которых успех достигается в m испытаниях, а неуспех - в n - m испытаниях. Рассмотрим один из таких вариантов - B 1 . По правилу сложения вероятностей умножаем вероятности противоположных событий:
![]() ,
,
а если обозначим q = 1 - p , то
![]() .
.
Такую же вероятность будет иметь любой другой вариант, в котором m успехов и n - m неуспехов. Число таких вариантов равно - числу способов, которыми можно из n испытаний получить m успехов.
Сумма вероятностей всех m чисел наступления события А (чисел от 0 до n ) равна единице:
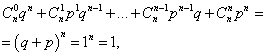
где каждое слагаемое представляет собой слагаемое бинома Ньютона. Поэтому рассматриваемое распределение и называется биномиальным распределением.
На практике часто необходимо вычислять вероятности "не более m успехов в n испытаниях" или "не менее m успехов в n испытаниях". Для этого используются следующие формулы.
Интегральную функцию, то есть вероятность F (m ) того, что в n наблюдениях событие А наступит не более m раз , можно вычислить по формуле:
В свою очередь вероятность F (≥m ) того, что в n наблюдениях событие А наступит не менее m раз , вычисляется по формуле:
Иногда бывает удобнее вычислять вероятность того, что в n наблюдениях событие А наступит не более m раз, через вероятность противоположного события:
![]() .
.
Какой из формул пользоваться, зависит от того, в какой из них сумма содержит меньше слагаемых.
Характеристики биномиального распределения вычисляются по следующим формулам .
Математическое ожидание: .
Дисперсия: .
Среднеквадратичное отклонение: .
Биномиальное распределение и расчёты в MS Excel
Вероятность биномиального распределения P n (m ) и значения интегральной функции F (m ) можно вычислить при помощи функции MS Excel БИНОМ.РАСП. Окно для соответствующего расчёта показано ниже (для увеличения нажать левой кнопкой мыши).
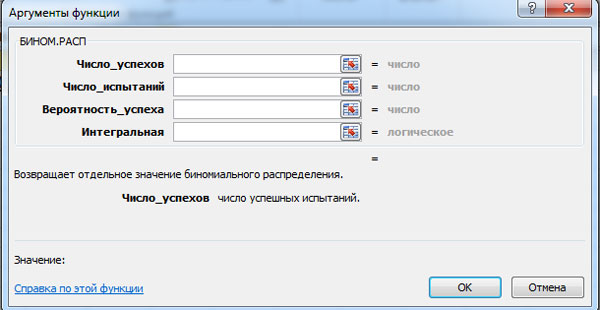
MS Excel требует ввести следующие данные:
- число успехов;
- число испытаний;
- вероятность успеха;
- интегральная - логическое значение: 0 - если нужно вычислить вероятность P n (m ) и 1 - если вероятность F (m ).
Пример 1. Менеджер фирмы обобщил информацию о числе проданных в течение последних 100 дней фотокамер. В таблице обобщена информация и рассчитаны вероятности того, что в день будет продано определённое число фотокамер.
День завершён с прибылью, если продано 13 или более фотокамер. Вероятность, что день будет отработан с прибылью:
![]()
Вероятность того, что день будет отработан без прибыли:
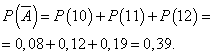
Пусть вероятность того, что день отработан с прибылью, является постоянной и равна 0,61, и число проданных в день фотокамер не зависит от дня. Тогда можно использовать биномиальное распределение, где событие А - день будет отработан с прибылью, - без прибыли.
Вероятность того, что из 6 дней все будут отработаны с прибылью:
![]() .
.
Тот же результат получим, используя функцию MS Excel БИНОМ.РАСП (значение интегральной величины - 0):
P 6 (6 ) = БИНОМ.РАСП(6; 6; 0,61; 0) = 0,052.
Вероятность того, что из 6 дней 4 и больше дней будут отработаны с прибылью:
где ![]() ,
,
![]() ,
,
Используя функцию MS Excel БИНОМ.РАСП, вычислим вероятность того, что из 6 дней не более 3 дней будут завершены с прибылью (значение интегральной величины - 1):
P 6 (≤3 ) = БИНОМ.РАСП(3; 6; 0,61; 1) = 0,435.
Вероятность того, что из 6 дней все будут отработаны с убытками:
![]() ,
,
Тот же показатель вычислим, используя функцию MS Excel БИНОМ.РАСП:
P 6 (0 ) = БИНОМ.РАСП(0; 6; 0,61; 0) = 0,0035.
Решить задачу самостоятельно, а затем посмотреть решение
Пример 2. В урне 2 белых шара и 3 чёрных. Из урны вынимают шар, устанавливают цвет и кладут обратно. Попытку повторяют 5 раз. Число появления белых шаров - дискретная случайная величина X , распределённая по биномиальному закону. Составить закон распределения случайной величины. Определить моду, математическое ожидание и дисперсию.
Продолжаем решать задачи вместе
Пример 3. Из курьерской службы отправились на объекты n = 5 курьеров. Каждый курьер с вероятностью p = 0,3 независимо от других опаздывает на объект. Дискретная случайная величина X - число опоздавших курьеров. Построить ряд распределения это случайной величины. Найти её математическое ожидание, дисперсию, среднее квадратическое отклонение. Найти вероятность того, что на объекты опоздают не менее двух курьеров.
Рассмотрим Биномиальное распределение, вычислим его математическое ожидание, дисперсию, моду. С помощью функции MS EXCEL БИНОМ.РАСП() построим графики функции распределения и плотности вероятности. Произведем оценку параметра распределения p, математического ожидания распределения и стандартного отклонения. Также рассмотрим распределение Бернулли.
Определение . Пусть проводятся n испытаний, в каждом из которых может произойти только 2 события: событие «успех» с вероятностью p или событие «неудача» с вероятностью q =1-p (так называемая Схема Бернулли, Bernoulli trials ).
Вероятность получения ровно x успехов в этих n испытаниях равна:
Количество успехов в выборке x является случайной величиной, которая имеет Биномиальное распределение (англ. Binomial distribution ) p и n – являются параметрами этого распределения.
Напомним, что для применения схемы Бернулли и соответственно Биномиального распределения, должны быть выполнены следующие условия:
- каждое испытание должно иметь ровно два исхода, условно называемых «успехом» и «неудачей».
- результат каждого испытания не должен зависеть от результатов предыдущих испытаний (независимость испытаний).
- вероятность успеха p должна быть постоянной для всех испытаний.
Биномиальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Биномиального распределения имеется функция БИНОМ.РАСП() , английское название - BINOM.DIST(), которая позволяет вычислить вероятность того, что в выборке будет ровно х «успехов» (т.е. функцию плотности вероятности p(x), см. формулу выше), и интегральную функцию распределения (вероятность того, что в выборке будет x или меньше «успехов», включая 0).
До MS EXCEL 2010 в EXCEL была функция БИНОМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности p(x). БИНОМРАСП() оставлена в MS EXCEL 2010 для совместимости.
В файле примера приведены графики плотности распределения вероятности и .

Биномиальное распределения имеет обозначение B (n ; p ) .
Примечание : Для построения интегральной функции распределения идеально подходит диаграмма типа График , для плотности распределения – Гистограмма с группировкой . Подробнее о построении диаграмм читайте статью Основные типы диаграмм.
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров Биномиального распределения : n и p.

В файле примера приведены различные расчеты вероятности с помощью функций MS EXCEL:

Как видно на картинке выше, предполагается, что:
- В бесконечной совокупности, из которой делается выборка, содержится 10% (или 0,1) годных элементов (параметр p , третий аргумент функции =БИНОМ.РАСП() )
- Чтобы вычислить вероятность, того что в выборке из 10 элементов (параметр n , второй аргумент функции) будет ровно 5 годных элементов (первый аргумент), нужно записать формулу: =БИНОМ.РАСП(5; 10; 0,1; ЛОЖЬ)
- Последний, четвертый элемент, установлен =ЛОЖЬ, т.е. возвращается значение функции плотности распределения .
Если значение четвертого аргумента =ИСТИНА, то функция БИНОМ.РАСП() возвращает значение интегральной функции распределения или просто Функцию распределения . В этом случае можно рассчитать вероятность того, что в выборке количество годных элементов будет из определенного диапазона, например, 2 или меньше (включая 0).
Для этого нужно записать формулу:
= БИНОМ.РАСП(2; 10; 0,1; ИСТИНА)
Примечание
: При нецелом значении х, . Например, следующие формулы вернут одно и тоже значение:
=БИНОМ.РАСП(2
; 10; 0,1; ИСТИНА)
=БИНОМ.РАСП(2,9
; 10; 0,1; ИСТИНА)
Примечание : В файле примера плотность вероятности и функция распределения также вычислены с использованием определения и функции ЧИСЛКОМБ() .
Показатели распределения
В файле примера на листе Пример имеются формулы для расчета некоторых показателей распределения:
- =n*p;
- (квадрата стандартного отклонения) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*КОРЕНЬ(n*p*(1-p)).
Выведем формулу математического ожидания Биномиального распределения , используя Схему Бернулли .
По определению случайная величина Х в схеме Бернулли (Bernoulli random variable) имеет функцию распределения :

Это распределение называется распределение Бернулли .
Примечание : распределение Бернулли – частный случай Биномиального распределения с параметром n=1.
Сгенерируем 3 массива по 100 чисел с различными вероятностями успеха: 0,1; 0,5 и 0,9. Для этого в окне Генерация случайных чисел установим следующие параметры для каждой вероятности p:

Примечание : Если установить опцию Случайное рассеивание (Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию =25 можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца по 100 чисел, на основании которых можно, например, оценить вероятность успеха p по формуле: Число успехов/100 (см. файл примера лист ГенерацияБернулли ).

Примечание : Для распределения Бернулли с p=0,5 можно использовать формулу =СЛУЧМЕЖДУ(0;1) , которая соответствует .
Генерация случайных чисел. Биномиальное распределение
Предположим, что в выборке обнаружилось 7 дефектных изделий. Это означает, что «очень вероятна» ситуация, что изменилась доля дефектных изделий p , которая является характеристикой нашего производственного процесса. Хотя такая ситуация «очень вероятна», но существует вероятность (альфа-риск, ошибка 1-го рода, «ложная тревога»), что все же p осталась без изменений, а увеличенное количество дефектных изделий обусловлено случайностью выборки.
Как видно на рисунке ниже, 7 – количество дефектных изделий, которое допустимо для процесса с p=0,21 при том же значении Альфа . Это служит иллюстрацией, что при превышении порогового значения дефектных изделий в выборке, p «скорее всего» увеличилось. Фраза «скорее всего» означает, что существует всего лишь 10% вероятность (100%-90%) того, что отклонение доли дефектных изделий выше порогового вызвано только сучайными причинами.

Таким образом, превышение порогового количества дефектных изделий в выборке, может служить сигналом, что процесс расстроился и стал выпускать бо льший процент бракованных изделий.
Примечание : До MS EXCEL 2010 в EXCEL была функция КРИТБИНОМ() , которая эквивалентна БИНОМ.ОБР() . КРИТБИНОМ() оставлена в MS EXCEL 2010 и выше для совместимости.
Связь Биномиального распределения с другими распределениями
Если параметр n
Биномиального распределения
стремится к бесконечности, а p
стремится к 0, то в этом случае Биномиальное распределение
может быть аппроксимировано .
Можно сформулировать условия, когда приближение распределением Пуассона
работает хорошо:
- p <0,1 (чем меньше p и больше n , тем приближение точнее);
- p >0,9 (учитывая, что q =1- p , вычисления в этом случае необходимо производить через q (а х нужно заменить на n - x ). Следовательно, чем меньше q и больше n , тем приближение точнее).
При 0,1<=p<=0,9 и n*p>10 Биномиальное распределение можно аппроксимировать .
В свою очередь, Биномиальное распределение может служить хорошим приближением , когда размер совокупности N Гипергеометрического распределения гораздо больше размера выборки n (т.е., N>>n или n/N<<1).
Подробнее о связи вышеуказанных распределений, можно прочитать в статье . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье .
Распределения вероятностей дискретных случайных величин. Биномиальное распределение. Распределение Пуассона. Геометрическое распределение. Производящая функция.
6. Распределения вероятностей дискретных случайных величин
6.1. Биномиальное распределение
Пусть производится n независимых испытаний, в каждом из которых событие A может либо появится, либо не появится. Вероятность p появления события A во всех испытаниях постоянна и не изменяется от испытания к испытанию. Рассмотрим в качестве случайной величины X число появлений события A в этих испытаниях. Формула, позволяющая найти вероятность появления события A ровно k раз в n испытаниях, как известно, описывается формулой Бернулли
Распределение вероятностей, определяемое формулой Бернулли, называется биномиальным .
Этот закон назван "биномиальным" потому, что правую часть можно рассматривать как общий член разложения бинома Ньютона
Запишем биномиальный закон в виде таблицы
|
p n |
np n –1 q |
|
q n |

Найдем числовые характеристики этого распределения.
По определению математического ожидания для ДСВ имеем
 .
.
Запишем равенство, являющееся бином Ньютона
 .
.
и продифференцируем его по p. В результате получим
 .
.
Умножим левую и правую часть на p :
 .
.
Учитывая, что p + q =1, имеем
 (6.2)
(6.2)
Итак, математическое ожидание числа появлений событий в n независимых испытаниях равно произведению числа испытаний n на вероятность p появления события в каждом испытании .
Дисперсию вычислим по формуле
 .
.
Для этого найдем
 .
.
Предварительно продифференцируем формулу бинома Ньютона два раза по p :

и умножим обе части равенства на p 2:

Следовательно,
Итак, дисперсия биномиального распределения равна
 .
(6.3)
.
(6.3)
Данные результаты можно получить и из чисто качественных рассуждений. Общее число X появлений события A во всех испытаниях складываются из числа появлений события в отдельных испытаниях. Поэтому если X 1 – число появлений события в первом испытании, X 2 – во втором и т.д., то общее число появлений события A во всех испытаниях равно X=X 1 +X 2 +…+X n . По свойству математического ожидания:
Каждое из слагаемых правой части равенства есть математическое ожидание числа событий в одном испытании, которое равно вероятности события. Таким образом,
По свойству дисперсии:
Так
как
,
а математическое ожидание случайной
величины ,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
 .
Таким образом,
.
Таким образом, В результате, получаем
В результате, получаем
Воспользовавшись понятием начальных и центральных моментов, можно получить формулы для асимметрии и эксцесса:
 .
(6.4)
.
(6.4)

Рис. 6.1
Многоугольник биномиального распределения имеет следующий вид (см. рис. 6.1). ВероятностьP n (k ) сначала возрастает при увеличении k , достигает наибольшего значения и далее начинает убывать. Биномиальное распределение асимметрично, за исключением случая p =0,5. Отметим, что при большом числе испытаний n биномиальное распределение весьма близко к нормальному. (Обоснование этого предложения связано с локальной теоремой Муавра-Лапласа.)Число m 0 наступлений события называется наивероятнейшим , если вероятность наступления события данное число раз в этой серии испытаний наибольшая (максимум в многоугольнике распределения) . Для биномиального распределения
Замечание. Данное неравенство можно доказать, используя рекуррентную формулу для биномиальных вероятностей:
 (6.6)
(6.6)
Пример 6.1. Доля изделий высшего сорта на данном предприятии составляет 31%. Чему равно математического ожидание и дисперсия, также наивероятнейшее число изделий высшего сорта в случайно отобранной партии из 75 изделий?
Решение. Поскольку p =0,31, q =0,69, n =75, то
M[X ] = np = 750,31 = 23,25; D[X ] = npq = 750,310,69 = 16,04.
Для нахождения наивероятнейшего числа m 0 , составим двойное неравенство
Отсюда следует, что m 0 = 23.
В отличие от нормального и равномерного распределений, описывающих поведение переменной в исследуемой выборке испытуемых, биномиальное распределение используется для иных целей. Оно служит для прогнозирования вероятности двух взаимоисключающих событий в некотором числе независимых друг от друга испытаний. Классический пример биномиального распределения – подбрасывание монеты, которая падает на твердую поверхность. Равновероятны два исхода (события): 1) монета падает «орлом» (вероятность равна р ) или 2) монета падает «решкой» (вероятность равна q ). Если третьего исхода не дано, то p = q = 0,5 и p + q = 1. Используя формулу биномиального распределения, можно определить, например, какова вероятность того, что в 50 испытаниях (число подбрасываний монеты) последняя выпадет «орлом», предположим, 25 раз.
Для дальнейших рассуждений введем общепринятые обозначения:
n – общее число наблюдений;
i – число интересующих нас событий (исходов);
n – i – число альтернативных событий;
p – эмпирически определенная (иногда – предполагаемая) вероятность интересующего нас события;
q – вероятность альтернативного события;
P n (i ) – прогнозируемая вероятность интересующего нас события i по определенному числу наблюдений n .
Формула биномиального распределения:
В случае равновероятного исхода событий (p = q ) можно использовать упрощенную формулу:
![]() (6.8)
(6.8)
Рассмотрим три примера, иллюстрирующие использование формул биномиального распределения в психологических исследованиях.
Пример 1
Предположим, что 3 студента решают задачу повышенной сложности. Для каждого из них равновероятны 2 исхода: (+) – решение и (-) – нерешение задачи. Всего возможно 8 разных исходов (2 3 = 8).
Вероятность того, что ни один студент не справится с задачей, равна 1/8 (вариант 8); 1 студент справится с задачей: P = 3/8 (варианты 4, 6, 7); 2 студента – P = 3/8 (варианты 2, 3, 5) и 3 студента – P =1/8 (вариант 1).
Необходимо определить вероятность того, что трое из 5 студентов успешно справятся с данной задачей.
Решение
Всего возможных исходов: 2 5 = 32.
Общее число вариантов 3(+) и 2(-) составляет

Следовательно, вероятность ожидаемого исхода равна 10/32 » 0,31.
Пример 3
Задание
Определить вероятность того, что в группе из 10 случайных испытуемых обнаружится 5 экстравертов.
Решение
1. Вводим обозначения: p = q = 0,5; n = 10; i = 5; P 10 (5) = ?
2. Используем упрощенную формулу (см. выше):
Вывод
Вероятность того, что среди 10 случайных испытуемых обнаружится 5 экстравертов, составляет 0,246.
Примечания
1. Вычисление по формуле при достаточно большом числе испытаний достаточно трудоемко, поэтому в этих случаях рекомендуется использовать таблицы биномиального распределения.
2. В некоторых случаях значения p и q можно задать изначально, но не всегда. Как правило, они вычисляются по результатам предварительных испытаний (пилотажных исследований).
3. В графическом изображении (в координатах P n (i ) = f (i )) биномиальное распределение может иметь различный вид: в случае p = q распределение симметрично и напоминает нормальное распределение Гаусса; асимметрия распределения тем больше, чем больше разница между вероятностями p и q .
Распределение Пуассона
Распределение Пуассона является частным случаем биномиального распределения, используемым при очень низкой вероятности интересующих нас событий. Другими словами, это распределение описывает вероятность редких событий. Формулой Пуассона можно пользоваться при p < 0,01 и q ≥ 0,99.
Уравнение Пуассона является приближенным и описывается следующей формулой:
![]() (6.9)
(6.9)
где μ представляет собой произведение средней вероятности события и числа наблюдений.
В качестве примера рассмотрим алгоритм решения следующей задачи.
Условие задачи
За несколько лет в 21 крупной клинике России было проведено массовое обследование новорожденных на предмет заболевания младенцев болезнью Дауна (выборка в среднем составляла 1000 новорожденных в каждой клинике). Были получены следующие данные:
Задание
1. Определить среднюю вероятность заболевания (в пересчете на число новорожденных).
2. Определить, на какое число новорожденных в среднем приходится одно заболевание.
3. Определить вероятность того, что среди 100 случайно выбранных новорожденных обнаружится 2 младенца с болезнью Дауна.
Решение
1. Определяем среднюю вероятность заболевания. При этом мы должны руководствоваться следующими рассуждениями. Болезнь Дауна зарегистрирована лишь в 10 клиниках из 21. В 11 клиниках заболеваний не обнаружено, в 6 клиниках зарегистрировано по 1 случаю, в 2 клиниках – 2 случая, в 1-й клинике – 3 и в 1-й клинике – 4 случая болезни. 5 случаев заболевания не было обнаружено ни в одной клинике. Для того чтобы определить среднюю вероятность заболевания, необходимо общее число случаев (6·1 + 2·2 + 1·3 + 1·4 = 17) разделить на общее число новорожденных (21000):
![]()
2. Число новорожденных, на которое приходится одно заболевание, является величиной обратной средней вероятности, т. е. равно общему числу новорожденных, отнесенному к числу зарегистрированных случаев:
![]()
3. Подставляем значения p = 0,00081, n = 100 и i = 2 в формулу Пуассона:
Ответ
Вероятность того, что среди 100 случайно выбранных новорожденных обнаружится 2 младенца с болезнью Дауна, составляет 0,003 (0,3%).
Задачи по теме
Задача 6. 1
Задание
Пользуясь данными задачи 5.1 по времени сенсомоторной реакции, вычислить асимметрию и эксцесс распределения ВР.
Задача 6. 2
200 учащихся выпускных классов были протестированы на уровень интеллектуальности (IQ ). После нормирования полученного распределения IQ по стандартному отклонению были получены следующие результаты:
Задание
Пользуясь критериями Колмогорова и хи-квадрат, определить, соответствует ли полученное распределение показателей IQ нормальному.
Задача 6. 3
У взрослого испытуемого (мужчина 25 лет) исследовалось время простой сенсомоторной реакции (ВР) в ответ на звуковой стимул с постоянной частотой в 1 кГц и интенсивностью 40 дБ. Стимул предъявлялся стократно с интервалами 3 – 5 секунд. Отдельные значения ВР по 100 повторностям распределилось следующим образом:
Задание
1. Построить частотную гистограмму распределения ВР; определить среднее значение ВР и величину стандартного отклонения.
2. Рассчитать коэффициент асимметрии и показатель эксцесса распределения ВР; на основании полученных значений As и Ex сделать вывод о соответствии или несоответствии данного распределения нормальному.
Задача 6. 4
В 1998 году в Нижнем Тагиле окончили школы с золотыми медалями 14 человек (5 юношей и 9 девушек), с серебряными – 26 человек (8 юношей и 18 девушек).
Вопрос
Можно ли утверждать, что девушки получают медали чаще, чем юноши?
Примечание
Соотношение числа юношей и девушек в генеральной совокупности считать равным.
Задача 6. 5
Считается, что число экстравертов и интровертов в однородной группе испытуемых является приблизительно одинаковым.
Задание
Определить вероятность того, что в группе из 10 случайно отобранных испытуемых обнаружится 0, 1, 2, ..., 10 экстравертов. Построить графическое выражение распределения вероятностей обнаружения 0, 1, 2, ..., 10 экстравертов в данной группе.
Задача 6. 6
Задание
Рассчитать вероятность P n (i) функции биномиального распределения при p = 0,3 и q = 0,7 для значений n = 5 и i = 0, 1, 2, ..., 5. Построить графическое выражение зависимости P n (i) = f (i).
Задача 6. 7
В последние годы среди определенной части населения утвердилась вера в астрологические прогнозы. По результатам предварительных опросов установлено, что в астрологию верят около 15% населения.
Задание
Определить вероятность того, что среди 10 случайно выбранных респондентов окажется 1, 2 или 3 человека, верящих в астрологические прогнозы.
Задача 6. 8
Условие задачи
В 42 общеобразовательных школах г. Екатеринбурга и Свердловской области (общее число учащихся 12260 человек) за несколько лет было выявлено следующее число случаев психических заболеваний среди школьников:
Задание
Пусть будет выборочно обследовано 1000 школьников. Рассчитать, какова вероятность того, что среди этой тысячи школьников будет выявлен 1, 2 или 3 психически больных ребенка?
РАЗДЕЛ 7. МЕРЫ РАЗЛИЧИЙ
Постановка проблемы
Предположим, что мы имеем две независимые друг от друга выборки испытуемых х и у . Независимыми выборки считаются тогда, когда один и тот же субъект (испытуемый) фигурирует только в одной выборке. Задача состоит в том, чтобы сравнить между собой эти выборки (два ряда переменных) на предмет их различий. Естественно, что как бы ни были близки между собой значения переменных в первой и второй выборке, какие-то, пусть даже незначительные, различия между ними будут обнаруживаться. С точки же зрения математической статистики нас интересует вопрос, являются ли различия между этими выборками статистически достоверными (статистически значимыми) или недостоверными (случайными).
Наиболее распространенными критериями достоверности различий между выборками являются параметрические меры различий – критерий Стьюдента и критерий Фишера . В ряде случаев используются непараметрические критерии – критерий Q Розенбаума, U-критерий Манна- Уитни и др. Особое место занимает угловое преобразование Фишера φ* , позволяющие сравнивать друг с другом значения, выраженные в процентах (процентных долях). И, наконец, как частный случай, для сравнения выборок могут быть использованы критерии, характеризующие форму распределений выборок – критерий χ 2 Пирсона и критерий λ Колмогорова – Смирнова .
В целях наилучшего усвоения данной темы мы поступим следующим образом. Одну и ту же задачу мы решим четырьмя методами с использованием четырех различных критериев – Розенбаума, Манна-Уитни, Стьюдента и Фишера.
Условие задачи
30 студентов (14 юношей и 16 девушек) во время экзаменационной сессии протестированы по тесту Спилбергера на уровень реактивной тревожности. Получены следующие результаты (табл. 7.1):
Таблица 7.1
| Испытуемые | Уровень реактивной тревожности | |||||||||||||||
| Юноши | ||||||||||||||||
| Девушки |
Задание
Определить, являются ли статистически достоверными различия уровня реактивной тревожности у юношей и девушек.
Задача представляется вполне типичной для психолога, специализирующегося в области педагогической психологии: кто более остро переживает экзаменационный стресс – юноши или девушки? Если различия между выборками статистически достоверны, то существуют значимые половые различия в данном аспекте; если различия случайны (статистически недостоверны), от данного предположения следует отказаться.
7. 2. Непараметрический критерий Q Розенбаума
Q -критерий Розенбаума основан на сравнении «наложенных» друг на друга ранжированных рядов значений двух независимых переменных. При этом не анализируется характер распределения признака внутри каждого ряда – в данном случае имеет значение лишь ширина неперекрывающихся участков двух ранжированных рядов. При сравнении между собой двух ранжированных рядов переменных возможны 3 варианта:
1. Ранжированные ряды x и y не имеют области перекрытия, т. е. все значения первого ранжированного ряда (x ) больше всех значений второго ранжированного ряда(y ):
В данном случае различия между выборками, определяемые по любому статистическому критерию, безусловно достоверны, и использование критерия Розенбаума не требуется. Тем не менее на практике такой вариант встречается исключительно редко.
2. Ранжированные ряды полностью накладываются друг на друга (как правило, один из рядов находится внутри другого), неперекрывающиеся зоны отсутствуют. В данном случае критерий Розенбаума неприменим.

3. Имеется зона перекрытия рядов, а также две неперекрывающиеся области (N 1 и N 2 ), относящиеся к разным ранжированным рядам (обозначим х – ряд, сдвинутый в сторону больших, y – в сторону меньших значений):

Данный случай является типичным для использования критерия Розенбаума, при использовании которого следует соблюдать следующие условия:
1. Объем каждой выборки должен быть не менее 11.
2. Объемы выборок не должны существенно отличаться друг от друга.
Критерий Q Розенбаума соответствует числу неперекрывающихся значений: Q = N 1 + N 2 . Вывод о достоверности различий между выборками делается в случае, если Q > Q кр. При этом значения Q кр находятся в специальных таблицах (см. Приложение, табл. VIII).
Вернемся к нашей задаче. Введем обозначения: х – выборка девушек, y – выборка юношей. Для каждой выборки строим ранжированный ряд:
х : 28 30 34 34 35 36 37 39 40 41 42 42 43 44 45 46
y : 26 28 32 32 33 34 35 38 39 40 41 42 43 44
Подсчитываем число значений в неперекрывающихся областях ранжированных рядов. В ряду х неперекрывающимися являются значения 45 и 46, т. е. N 1 = 2;в ряду y только 1 неперекрывающееся значение 26, т. е. N 2 = 1. Отсюда, Q = N 1 + N 2 = 1 + 2 = 3.
В табл. VIII Приложения находим, что Q кр . = 7 (для уровня значимости 0,95) и Q кр = 9 (для уровня значимости 0,99).
Вывод
Поскольку Q < Q кр, то по критерию Розенбаума различия между выборками не являются статистически достоверными.
Примечание
Критерий Розенбаума может использоваться независимо от характера распределения переменных, т. е. в данном случае отпадает необходимость использования критериев χ 2 Пирсона и λ Колмогорова для определения типа распределений в обеих выборках.
7. 3. U -критерий Манна – Уитни
В отличие от критерия Розенбаума, U -критерий Манна – Уитни основан на определении зоны перекрытия между двумя ранжированными рядами, т. е. чем меньше зона перекрытия, тем достовернее различия между выборками. Для этого используется специальная процедура преобразования интервальных шкал в ранговые.
Рассмотрим алгоритм вычислений по U -критерию на примере предыдущей задачи.
Таблица 7.2
| x, y | R xy | R xy * | R x | R y |
| 26 28 32 32 33 34 35 38 39 40 41 42 43 44 | 2,5 2,5 5,5 5,5 11,5 11,5 16,5 16,5 18,5 18,5 20,5 20,5 25,5 25,5 27,5 27,5 | 2,5 11,5 16,5 18,5 20,5 25,5 27,5 | 1 2,5 5,5 5,5 7 9 11,5 15 16,5 18,5 20,5 23 25,5 27,5 | |
| Σ | 276,5 | 188,5 |
1. Из двух независимых выборок строим единый ранжированный ряд. В данном случае значения для обеих выборок идут «вперемешку», столбец 1 (x , y ). В целях упрощения дальнейшей работы (в том числе и в компьютерном варианте) следует значения для разных выборок отмечать разным шрифтом (или разным цветом) с учетом того, что в дальнейшем мы будем их разносить по разным столбцам.
2. Преобразуем интервальную шкалу значений в порядковую (для этого переобозначаем все значения ранговыми числами от 1 до 30, столбец 2 (R xy)).
3. Вводим поправки на связанные ранги (одинаковые значения переменной обозначаются одним и тем же рангом при условии, что сумма рангов не изменяется, столбец 3 (R xy *). На этом этапе рекомендуется подсчитать суммы рангов во 2-м и 3-м столбце (если все поправки введены верно, то эти суммы должны быть равны).
4. Разносим ранговые числа в соответствии с их принадлежностью к той или иной выборке (столбцы 4 и 5 (R x и R y)).
5. Проводим вычисления по формуле:
![]() (7.1)
(7.1)
где Т х – наибольшая из ранговых сумм; n x и n y , соответственно, объемы выборок. В данном случае следует иметь в виду, что если T x < T y , то обозначения x и y следует сменить на обратные.
6. Сравниваем полученное значение с табличным (см. Приложения, табл. IX).Вывод о достоверности различий между двумя выборками делается в случае, если U эксп. < U кр. .
В нашем примере ![]() U
эксп. = 83,5 > U кр.
= 71.
U
эксп. = 83,5 > U кр.
= 71.
Вывод
Различия между двумя выборками по критерию Манна – Уитни не являются статистически достоверными.
Примечания
1. Критерий Манна-Уитни не имеет практически никаких ограничений; минимальные объемы сравниваемых выборок – 2 и 5 человек (см. табл. IX Приложения).
2. Аналогично критерию Розенбаума критерий Манна-Уитни может быть использован применительно к любым выборкам независимо от характера распределения.
Критерий Стьюдента
В отличие от критериев Розенбаума и Манна-Уитни критерий t Стьюдента является параметрическим, т. е. основан на определении основных статистических показателей – средних значений в каждой выборке ( и ) и их дисперсий (s 2 x и s 2 y), рассчитываемых по стандартным формулам (см. раздел 5).
Использование критерия Стьюдента предполагает соблюдение следующих условий:
1. Распределения значений для обеих выборок должны соответствовать закону нормального распределения (см. раздел 6).
2. Суммарный объем выборок должен быть не менее 30 (для β 1 = 0,95) и не менее 100 (для β 2 = 0,99).
3. Объемы двух выборок не должны существенно отличаться друг от друга (не более чем в 1,5 ÷ 2 раза).
Идея критерия Стьюдента достаточно проста. Предположим, что значения переменных в каждой из выборок распределяются по нормальному закону, т. е. мы имеем дело с двумя нормальными распределениями, отличающимися друг от друга по средним значениям и дисперсии (соответственно и , и , см. рис. 7.1).

s x s y
Рис. 7.1. Оценка различий между двумя независимыми выборками: и - средние значения выборок x и y ; s x и s y - стандартные отклонения
Нетрудно понять, что различия между двумя выборками будут тем больше, чем больше разность между средними значениями и чем меньше их дисперсии (или стандартные отклонения).
В случае независимых выборок коэффициент Стьюдента определяют по формуле:
 (7.2)
(7.2)
где n x и n y – соответственно численность выборок x и y .
После вычисления коэффициента Стьюдента в таблице стандартных (критических) значений t (см. Приложение, табл. Х) находят величину, соответствующую числу степеней свободы n = n x + n y – 2, и сравнивают ее с рассчитанной по формуле. Если t эксп. £ t кр. , то гипотезу о достоверности различий между выборками отвергают, если же t эксп. > t кр. , то ее принимают. Другими словами, выборки достоверно отличаются друг от друга, если вычисленный по формуле коэффициент Стьюдента больше табличного значения для соответствующего уровня значимости.
В рассмотренной нами ранее задаче вычисление средних значений и дисперсий дает следующие значения: x ср. = 38,5; σ х 2 = 28,40; у ср. = 36,2; σ у 2 = 31,72.
Можно видеть, что среднее значение тревожности в группе девушек выше, чем в группе юношей. Тем не менее эти различия настолько незначительны, что вряд ли они являются статистически значимыми. Разброс значений у юношей, напротив, несколько выше, чем у девушек, но различия между дисперсиями также невелики.

Вывод
t эксп. = 1,14 < t кр. = 2,05 (β 1 = 0,95). Различия между двумя сравниваемыми выборками не являются статистически достоверными. Данный вывод вполне согласуется с таковым, полученным при использовании критериев Розенбаума и Манна-Уитни.
Другой способ определения различий между двумя выборками по критерию Стьюдента состоит в вычислении доверительного интервала стандартных отклонений. Доверительным интервалом называется среднеквадратичное (стандартное) отклонение, деленное на корень квадратный из объема выборки и умноженное на стандартное значение коэффициента Стьюдента для n – 1 степеней свободы (соответственно, и ).
Примечание
Величина = m x называется среднеквадратичной ошибкой (см. раздел 5). Следовательно, доверительный интервал есть среднеквадратичная ошибка, умноженная на коэффициент Стьюдента для данного объема выборки, где число степеней свободы ν = n – 1, и заданного уровня значимости.
Две независимые друг от друга выборки считаются достоверно различающимися, если доверительные интервалы для этих выборок не перекрываются друг с другом. В нашем случае мы имеем для первой выборки 38,5 ± 2,84, для второй 36,2 ± 3,38.
Следовательно, случайные вариации x i лежат в диапазоне 35,66 ¸ 41,34, а вариации y i – в диапазоне 32,82 ¸ 39,58. На основании этого можно констатировать, что различия между выборками x и y статистически недостоверны (диапазоны вариаций перекрываются друг с другом). При этом следует иметь в виду, что ширина зоны перекрытия в данном случае не имеет значения (важен лишь сам факт перекрытия доверительных интервалов).
Метод Стьюдента для зависимых друг от друга выборок (например, для сравнения результатов, полученных при повторном тестировании на одной и той же выборке испытуемых) используют достаточно редко, поскольку для этих целей существуют другие, более информативные статистические приемы (см. раздел 10). Тем не менее, для данной цели в первом приближении можно использовать формулу Стьюдента следующего вида:
 (7.3)
(7.3)
Полученный результат сравнивают с табличным значением для n – 1 степеней свободы, где n – число пар значений x и y . Результаты сравнения интерпретируются точно так же, как и в случае вычисления различий между двумя независимыми выборками.
Критерий Фишера
Критерий Фишера (F ) основан на том же принципе, что и критерий Стьюдента, т. е. предполагает вычисление средних значений и дисперсий в сравниваемых выборках. Чаще всего используется при сравнении между собой неравноценных по объему (разных по численности) выборок. Критерий Фишера является несколько более жестким, чем критерий Стьюдента, а потому более предпочтителен в тех случаях, когда возникают сомнения в достоверности различий (например, если по критерию Стьюдента различия достоверны при нулевом и недостоверны при первом уровне значимости).
Формула Фишера выглядит следующим образом:
 (7.4)
(7.4)
где и  (7.5, 7.6)
(7.5, 7.6)
В рассматриваемой нами задаче d 2 = 5,29; σ z 2 = 29,94.
Подставляем значения в формулу: ![]()
В табл. ХI Приложений находим, что для уровня значимости β 1 = 0,95 и ν = n x + n y – 2 = 28 критическое значение составляет 4,20.
Вывод
F = 1,32 < F кр. = 4,20. Различия между выборками статистически недостоверны.
Примечание
При использовании критерия Фишера должны соблюдаться те же условия, что и для критерия Стьюдента (см. подраздел 7.4). Тем не менее допускается различие в численности выборок более чем в два раза.
Таким образом, при решении одной и той же задачи четырьмя различными методами с использованием двух непараметрических и двух параметрических критериев мы пришли к однозначному выводу о том, что различия между группой девушек и группой юношей по уровню реактивной тревожности недостоверны (т. е. находятся в пределах случайных вариаций). Однако могут встретиться и такие случаи, когда сделать однозначный вывод не представляется возможным: одни критерии дают достоверные, другие – недостоверные различия. В этих случаях приоритет отдается параметрическим критериям (при условии достаточности объема выборок и нормального распределения исследуемых величин).
7. 6. Критерий j* - угловое преобразование Фишера
Критерий j*Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта. Он оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект. Допускается также сравнение процентных соотношений и в пределах одной выборки.
Суть углового преобразования Фишера состоит в переводе процентных долей в величины центрального угла, который измеряется в радианах. Большей процентной доле будет соответствовать больший угол j , а меньшей доле – меньший угол, но отношения здесь нелинейные:
![]()
где Р – процентная доля, выраженная в долях единицы.
При увеличении расхождения между углами j 1 и j 2 и увеличении численности выборок значение критерия возрастает.
Критерий Фишера вычисляется по следующей формуле:
| |
где j 1 – угол, соответствующий большей процентной доле; j 2 – угол, соответствующий меньшей процентной доле; n 1 и n 2 – соответственно, объем первой и второй выборок.
Вычисленное по формуле значение сравнивается со стандартным (j* ст = 1,64 для b 1 = 0,95 и j* ст = 2,31 для b 2 = 0,99. Различия между двумя выборками считаются статистически достоверными, если j*> j* ст для данного уровня значимости.
Пример
Нас интересует, различаются ли между собой две группы студентов по успешности выполнения достаточно сложной задачи. В первой группе из 20 человек с ней справилось 12 студентов, во второй – 10 человек из 25.
Решение
1. Вводим обозначения: n 1 = 20, n 2 = 25.
2. Вычисляем процентные доли Р 1 и Р 2: Р 1 = 12 / 20 = 0,6 (60%), Р 2 = 10 / 25 = 0,4 (40%).
3. В табл. XII Приложений находим соответствующие процентным долям значения φ: j 1 = 1,772, j 2 = 1,369.
| |
Отсюда:
Вывод
Различия между группами не являются статистически достоверными, поскольку j* < j* ст для 1-го и тем более для 2-го уровня значимости.
7.7. Использование критерия χ2 Пирсона и критерия λ Колмогорова
Теория вероятности незримо присутствует в нашей жизни. Мы не обращаем на это внимания, но каждое событие в нашей жизни имеет ту или иную вероятность. Принимая во внимание огромное количество вариантов развития событий, нам становится необходимым определять наиболее вероятные и наименее вероятные из них. Наиболее удобно анализировать такие вероятностные данные графически. В этом нам может помочь распределение. Биномиальное - одно из самых лёгких и самых точных.
Прежде чем перейти непосредственно к математике и теории вероятности, разберёмся с тем, кто же первый придумал такой вид распределения и какова история развития математического аппарата для этого понятия.
История
Понятие вероятности известно ещё с древних времён. Однако древние математики не придавали ей особо значения и смогли заложить только основы для теории, ставшей впоследствии теорией вероятности. Они создали некоторые комбинаторные методы, которые сильно помогли тем, кто позже создал и развил саму теорию.
Во второй половине семнадцатого века началось формирование основных понятий и методов теории вероятности. Были введены определения случайных величин, способы вычисления вероятности простых и некоторых сложных независимых и зависимых событий. Продиктован такой интерес к случайным величинам и вероятностям был азартными играми: каждый человек хотел знать, какие у него шансы победить в игре.
Следующим этапом стало применение в теории вероятности методов математического анализа. Этим занялись видные математики, такие как Лаплас, Гаусс, Пуассон и Бернулли. Именно они продвинули эту область математики на новый уровень. Именно Джеймс Бернулли открыл биномиальный закон распределения. Кстати, как мы позже выясним, на основе этого открытия были сделаны ещё несколько, которые позволили создать закон нормального распределения и ещё множество других.
Сейчас, прежде чем начать описывать распределение биномиальное, мы немного освежим в памяти понятия теории вероятностей, наверняка уже забытые со школьной скамьи.
Основы теории вероятностей
Будем рассматривать такие системы, в результате действия которых возможны только два исхода: "успех" и "не успех". Это легко понять на примере: мы подбрасываем монетку, загадав то, что выпадет решка. Вероятности каждого из возможных событий (выпадет решка - "успех", выпадет орёл - "не успех") равны 50 процентам при идеальной балансировке монеты и отсутствии прочих факторов, которые могут повлиять на эксперимент.
Это было самое простое событие. Но бывают ещё и сложные системы, в которых выполняются последовательные действия, и вероятности исходов этих действий будут различаться. Например, рассмотрим такую систему: в коробке, содержимое которой мы не можем разглядеть, лежат шесть абсолютно одинаковых шариков, три пары синего, красного и белого цветов. Мы должны достать наугад несколько шариков. Соответственно, вытащив первым один из белых шариков, мы уменьшим в разы вероятность того, что следующим нам тоже попадётся белый шарик. Происходит это потому, что меняется количество объектов в системе.
В следующем разделе рассмотрим более сложные математические понятия, вплотную подводящие нас к тому, что означают слова "нормальное распределение", "биномиальное распределение" и тому подобные.

Элементы математической статистики
В статистике, которая является одной из областей применения теории вероятностей, существует множество примеров, когда данные для анализа даны не в явном виде. То есть не в численном, а в виде разделения по признакам, например, по половым. Для того чтобы применить к таким данным математический аппарат и сделать из полученных результатов какие-то выводы, требуется перевести исходные данные в числовой формат. Как правило, для осуществления этого положительному исходу присваивают значение 1, а отрицательному - 0. Таким образом, мы получаем статистические данные, которые можно подвергнуть анализу с помощью математических методов.
Следующий шаг в понимании того, что такое биномиальное распределение случайной величины, - это определение дисперсии случайной величины и математического ожидания. Об этом поговорим в следующем разделе.

Математическое ожидание
На самом деле понять то, что такое математическое ожидание, несложно. Рассмотрим систему, в которой существует много разных событий со своими различными вероятностями. Математическим ожиданием будет называться величина, равная сумме произведений значений этих событий (а математическом виде, о котором мы говорили в прошлом разделе) на вероятности их осуществления.
Математическое ожидание биномиального распределения рассчитывается по той же самой схеме: мы берём значение случайной величины, умножаем его на вероятность положительного исхода, а затем суммируем полученные данные для всех величин. Очень удобно представить эти данные графически - так лучше воспринимается разница между математическими ожиданиями разных величин.
В следующем разделе мы расскажем вам немного о другом понятии - дисперсии случайной величины. Оно тоже тесно связано с таким понятием, как биномиальное распределение вероятностей, и является его характеристикой.

Дисперсия биномиального распределения
Эта величина тесно связана с предыдущей и также характеризует распределение статистических данных. Она представляет собой средний квадрат отклонений значений от их математического ожидания. То есть дисперсия случайной величины - это сумма квадратов разностей между значением случайной величины и её математическим ожиданием, умноженная на вероятность этого события.
В общем, это всё, что нам нужно знать о дисперсии для понимания того, что такое биномиальное распределение вероятностей. Теперь перейдём непосредственно к нашей основной теме. А именно к тому, что же кроется за таким на вид достаточно сложным словосочетанием "биномиальный закон распределения".

Биномиальное распределение
Разберёмся для начала, почему же это распределение биномиальное. Оно происходит от слова "бином". Может быть, вы слышали о биноме Ньютона - такой формуле, с помощью которой можно разложить сумму двух любых чисел a и b в любой неотрицательной степени n.
Как вы, наверное, уже догадались, формула бинома Ньютона и формула биномиального распределения - это практически одинаковые формулы. За тем лишь исключением, что вторая имеет прикладное значение для конкретных величин, а первая - лишь общий математический инструмент, применения которого на практике могут быть различны.
Формулы распределения
Функция биномиального распределения может быть записана в виде суммы следующих членов:
(n!/(n-k)!k!)*p k *q n-k
Здесь n - число независимых случайных экспериментов, p- число удачных исходов, q- число неудачных исходов, k - номер эксперимента (может принимать значения от 0 до n),! - обозначение факториала, такой функции числа, значение которой равно произведению всех идущих до неё чисел (например, для числа 4: 4!=1*2*3*4=24).
Помимо этого, функция биномиального распределения может быть записана в виде неполной бета-функции. Однако это уже более сложное определение, которое используется только при решении сложных статистических задач.
Биномиальное распределение, примеры которого мы рассмотрели выше, - одно из самых простых видов распределений в теории вероятностей. Существует также нормальное распределение, являющееся одним из видов биномиального. Оно используется чаще всего, и наиболее просто в расчётах. Бывает также распределение Бернулли, распределение Пуассона, условное распределение. Все они характеризуют графически области вероятности того или иного процесса при разных условиях.
В следующем разделе рассмотрим аспекты, касающиеся применения этого математического аппарата в реальной жизни. На первый взгляд, конечно, кажется, что это очередная математическая штука, которая, как обычно, не находит применения в реальной жизни, и вообще не нужна никому, кроме самих математиков. Однако это далеко не так. Ведь все виды распределений и их графические представления были созданы исключительно под практические цели, а не в качестве прихоти учёных.

Применение
Безусловно, самое важное применение распределения находят в статистике, ведь там нужен комплексный анализ множества данных. Как показывает практика, очень многие массивы данных имеют примерно одинаковые распределения величин: критические области очень низких и очень высоких величин, как правило, содержат меньше элементов, чем средние значения.
Анализ больших массивов данных требуется не только в статистике. Он незаменим, например, в физической химии. В этой науке он используется для определения многих величин, которые связаны со случайными колебаниями и перемещениями атомов и молекул.
В следующем разделе разберёмся, насколько важно применение таких статистических понятий, как биномиальное распределение случайной величины в повседневной жизни для нас с вами.

Зачем мне это нужно?
Многие задают себе такой вопрос, когда дело касается математики. А между прочим, математика не зря называется царицей наук. Она является основой физики, химии, биологии, экономики, и в каждой из этих наук применяется в том числе и какое-либо распределение: будь это дискретное биномиальное распределение, или же нормальное, не важно. И если мы получше присмотримся к окружающему миру, то увидим, что математика применяется везде: в повседневной жизни, на работе, да даже человеческие отношения можно представить в виде статистических данных и провести их анализ (так, кстати, и делают те, кто работают в специальных организациях, занимающихся сбором информации).
Сейчас поговорим немного о том, что же делать, если вам нужно знать по данной теме намного больше, чем то, что мы изложили в этой статье.
Та информация, что мы дали в этой статье, далеко не полная. Существует множество нюансов, касаемо того, какую форму может принимать распределение. Биномиальное распределение, как мы уже выяснили, является одним из основных видов, на котором зиждется вся математическая статистика и теория вероятностей.
Если вам стало интересно, или в связи с вашей работой вам нужно знать по этой теме гораздо больше, нужно будет изучить специализированную литературу. Начать следует с университетского курса математического анализа и дойти там до раздела теории вероятностей. Также пригодятся знания в области рядов, ведь биномиальное распределение вероятностей - это ни что иное, как ряд последовательных членов.
Заключение
Прежде чем закончить статью, мы хотели бы рассказать ещё одну интересную вещь. Она касается непосредственно темы нашей статьи и всей математики в целом.
Многие люди твердят, что математика - бесполезная наука, и ничто из того, что они проходили в школе, им не пригодилось. Но знание ведь никогда не бывает лишним, и если вам что-то не пригодилось в жизни, значит, вы просто этого не помните. Если у вас есть знания, они могут вам помочь, но если их нет, то и помощи от них ждать не приходится.
Итак, мы рассмотрели понятие биномиального распределения и все связанные с ним определения и поговорили о том, как же это применяется в нашей с вами жизни.


